Natural language processing in finance: Shakespeare without the monkeys
By Slavi Marinov, Man AHL
Published: 27 September 2019
Introduction
“We want Facebook to be somewhere where you can start meaningful relationships,” Mark Zuckerberg said on 1 May, 2018.
The announcement sparked gasps – not just from the crowd in front of whom Zuckerberg was talking – but also in financial markets. The share price of Match Group (the company that owns Match.com, Tinder and other dating websites) plunged by more than 20%.
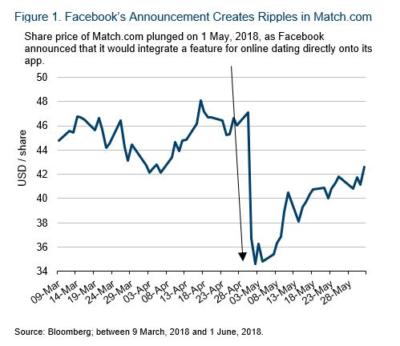
Why is this example significant? The answer is simple: Financial markets were being swayed by a sentence made up of just a few words. There was not a single number in the announcement. More interestingly, Zuckerberg’s comment did not impact Facebook’s share price – the biggest effect was felt by a company that until that moment may not have even been considered a competitor to Facebook. The move was large, and almost instantaneous.
This behaviour – a few words causing strong reactions rippling through markets – happens all the time, albeit usually more subtly. The focus of this article is the automatic analysis of text by computers, also known as Natural Language Processing (‘NLP’), which aims to extract meaning from words and predict the ripples even as they are happening.
What Is NLP?
NLP is a sub-field of artificial intelligence (‘AI’), which seeks to program computers to process, understand and analyse large amounts of human (or ‘natural’) language.
How is this useful in finance?
Detecting Material Events
As we saw in the Facebook example, it’s useful in uncovering market-moving events. Facebook unveiled a new product – like Apple unveiling the iPhone – and that resulted in a very strong market move. Numerous such events happen in financial markets all the time. Indeed, for a lot of them, text, or even the spoken word, is the primary source. As such, methods from NLP can be used to automate this process: monitoring many text data streams and automatically issuing notifications upon the emergence of market-moving events.
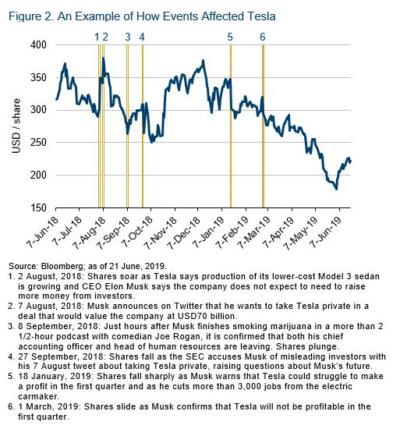
There are, however, many other ways in which machines can help.
Understanding Document Tone
Perhaps one of the most common applications of NLP in finance is measuring document tone, also known as sentiment. The idea is simple: get the machine to ‘read’ a document and assign it a score from -10 (very negative) to +10 (very positive).
Take the sentence below:
French Cosmetics giant L’Oreal said strong demand for luxury skin creams helped it beat fourth-quarter sales forecasts - another company reporting better-than-feared demand from China after LVMH last week.1
This would maybe get a score of 8.
Now take this sentence:
Construction was a weak spot with Denmark’s Rockwool sinking 13% after full-year earnings missed expectations, and Sweden’s Skanska losing 7.8% after it cut its dividend and lagged profit estimates.
This may get a score of -9 for Rockwool and Skanska.
While the two examples above are company-specific, sentiment analysis can also be done with respect to the economy in general, or even toward specific topics such as inflation or interest rates.
Modelling Document Topics
To be successful, NLP systems in finance often need to automatically extract a document’s topic structure. Consider this snippet from a news article:
Oil prices fell on Monday after climbing to their highest this year earlier in the session as China reported automobile sales in January fell for a seventh month, raising concerns about fuel demand in the world’s second-largest oil user.2
Often, the important information in a document is not just the tone, but its focus. In this example, there are two key topics: the first is oil, with words such as “oil”, “prices”, “fuel”, “fell” and “climb”; the second is the global economy, with words such as “world”, “China”, “demand” and “sales”. Understanding the topic structure of a document helps identifying events, informs the correct attribution of sentiment and allows to assess document similarity on a semantic level.
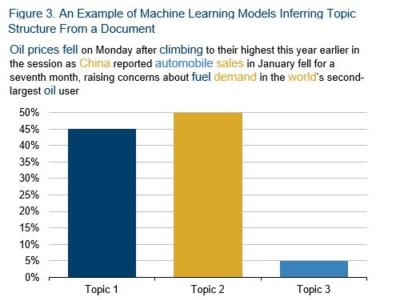
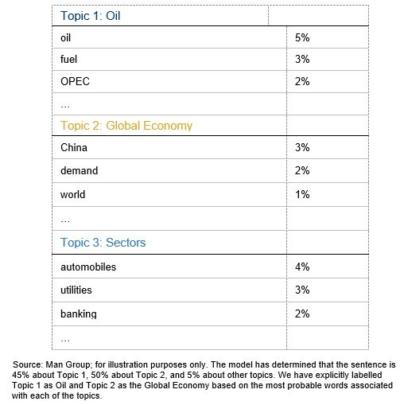
The above example also highlights another subtle, but important, aspect of quantifying text data: timeliness. Even if we correctly identified the document’s topics, there are two timeframes mentioned: “fell on Monday” and “climbing to their highest this year earlier in the session”. Clearly, these two moves were attributed to a single entity – oil prices – yet they have opposite directions. Correctly identifying the evolution of events can be a crucial task for computer algorithms.
Detecting Subtle Change
This theme of subtlety is quite prevalent in NLP research. The information contained in text data is sometimes very obvious to the human eye (a new product launch in the news; lots of positive words by a company executive), but can just as often be buried. One example application of NLP is measuring textual change: comparing the same documents over time, and finding subtle differences.
For example, in IBM’s 2016 annual report, the company had a snippet related to its brand risks under a risk factor called “Failure of Innovation Initiatives”. In the following year’s annual report, IBM decided to extract it as a separate risk factor called “Damage to IBM’s Reputation”, and explicitly listed eight broad categories of example sources of reputation risk.
Figure 4. Comaring IBM's Annual Reports
| IBM’s 2016 annual report3 | IBM’s 2017 annual report4 |
|
[…] IBM has one of the strongest brand names in the world, and its brand and overall reputation could be negatively impacted by many factors, including if the company does not continue to be recognized for its industry-leading technology and solutions and as a cognitive leader. If the company's brand image is tarnished by negative perceptions, its ability to attract and retain customers could be impacted. |
Damage to IBM's Reputation Could Impact the Company's Business: IBM has one of the strongest brand names in the world, and its brand and overall reputation could be negatively impacted by many factors, including if the company does not continue to be recognized for its industry-leading technology and solutions and as a cognitive leader. IBM's reputation is potentially susceptible to damage by events such as significant disputes with clients, product defects, internal control deficiencies, delivery failures, cybersecurity incidents, government investigations or legal proceedings or actions of current or former clients, directors, employees, competitors, vendors, alliance partners or joint venture partners. If the company's brand image is tarnished by negative perceptions, its ability to attract and retain customers could be impacted. |
Such subtle changes can be tricky and painstaking for a human to identify, especially given the typical length of annual reports and an investible universe of thousands of companies. Yet, to a machine, these changes are obvious: an algorithm can automatically scan through millions of documents and identify the added, deleted, or modified risk factors, classify them according to their topic, and even check which other companies have modified their risk factors in similar ways. Another example is the transcripts from the Federal Open Market Committee (‘FOMC’) on US interest rate policy, where the market typically reacts not to the current transcript, but rather to slight changes in wording between the current and previous ones.
Working Across Multiple Languages
All of the above examples are in English. While documents in English are convenient to consider because there is a vast amount of academic research in the area, it clearly isn’t the case that all market-moving information originates in English. To be able to leverage text from different languages and sources, one has to either develop models specific to that language, or translate documents into English and then apply an English model. Both applications are currently a heavy focus of NLP.
Going Beyond Written Text
All examples so far assume that the text we are interested in already exists in written form. That is not always the case. For example, every quarter, many global public companies host earnings conference calls – the timeliest source of financial results.5 Techniques from speech recognition research can be used to automatically transcribe documents as the call is progressing, or even analyse the subtle nuances of management tone to measure emotions.6
Why Should We Care About NLP Now?
In the last 10 years, we witnessed a major wave of scientific breakthroughs. These innovations come from the field of neural networks – also known as deep learning.
Neural network models get their inspiration from the human brain. Building blocks, called artificial neurons, are connected together, in code, to form larger networks. These neurons take some raw input data, fire up and transfer their impulses forward, ultimately resulting in a prediction. A researcher can define the ‘shape’ of the network: the connectivity pattern between the neurons. By designing different layouts and stacking them on top of one another (hence the name, ‘deep’ learning), researchers can impose their prior knowledge of the world. Given sufficiently large and complex datasets and compute resources, the strength of the connections between the artificial neurons can be learned. The researchers can create the blueprint (called the ‘architecture’), supply the data and guide the learning process; the neural networks adjust the neuron connection strengths to make the most accurate predictions.
Neural network models have successfully modelled problems ranging from how to represent the meaning of words in a computer (word embeddings7,8,9), through capturing the meaning of chunks of words (convolutional neural networks10,11,12), to modelling the sequential (recurrent neural networks13,14,15), and compositional (recursive neural networks16) nature of phrases. Indeed, these ideas have been the foundation of many of the recent state of-the-art results in modern NLP.
Challenges When Using NLP
The first obvious challenge is scale. Unlike many numerical datasets, text data can be very large and thus requires significant investments in data storage and computation capacities.
The next challenge is that ‘natural’ language often doesn’t do a particularly good job of conforming to cleanly defined grammatical rules. Some datasets you may want to look at in finance – such as annual reports or press releases – are carefully written and reviewed, and are largely grammatically correct. They are thus relatively easy for a computer to analyse. But how about tweets, product reviews or online forum comments? These tend to be full of abbreviations, slang, incomplete sentences, emoticons, etc – all of which make it quite tricky for a machine to decipher.
Perhaps the ultimate challenge is talent. To make sense of text data, experts from the fields of linguistics, machine learning and computer science need to be hired. In today’s highly competitive market, one needs to compete in the talent war for the best and brightest.
Conclusion
We believe NLP is an extremely exciting research area in finance due to the vast range of problems it can tackle for both quant and discretionary fund managers. In particular, firms with strong investments in technology infrastructure and machine learning talent have positioned themselves to potentially capitalise on successfully applying these methods to finance.
Combined with the availability of more data than ever, vast amounts of available compute and improved tools17,18,19,20, these exciting recent research advances may create a rich and fruitful alpha opportunity.
Footnotes
2. Source: Reuters.
3. https://www.sec.gov/Archives/edgar/data/51143/000104746917001061/a2230222z10-k.htm
4. https://www.sec.gov/Archives/edgar/data/51143/000104746918001117/a2233835z10-k.htm
6. William Mayhew and Mohan Venkatachalam (2012), The Power of Voice: Managerial Affective States and Future Firm Performance, Journal of Finance.
7. Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean (2013); Efficient Estimation of Word Representations in Vector Space.
8. Jeffrey Pennington, Richard Socher, Christopher D. Manning, GloVe: Global Vectors for Word Representation.
9. Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov (2016); Bag of Tricks for Efficient Text Classification.
10. Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, Pavel Kuksa (2011); Natural Language Processing (Almost) from Scratch.
11. Nal Kalchbrenner, Edward Grefenstette, Phil Blunsom (2014); A Convolutional Neural Network for Modelling Sentences.
12. Yoon Kim (2014); Convolutional Neural Networks for Sentence Classification.
13. Tomáš Mikolov, Martin Karafiát, Lukáš Burget, Jan “Honza” Cernocký, Sanjeev Khudanpur (2010); Recurrent neural network based language model.
14. Shujie Liu , Nan Yang , Mu Li and Ming Zhou (2014); A Recursive Recurrent Neural Network for Statistical Machine Translation.
15. Tony Robinson, Mike Hochberg and Steve Renals (1996); The Use of Recurrent Neural Networks in Continuous Speech Recognition.
16. Richard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng and Christopher Potts; Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank.
17. https://www.tensorflow.org/